LangGraph 入门
LangGraph 入门
LangGraph 入门
本文系统介绍 LangGraph 的核心概念、环境配置、用法及实践。内容涵盖 UV 包管理介绍、LangGraph 流程图模型、状态管理、节点与边、条件分支、持久化、流式输出等,配以详细代码示例,助你高效上手与理解。
代码地址 gitee
代码中提供了一些基础图形的构建案例
提供了一个综合案例-text-to-sql的案例,该案例将自然语言转为sql语句,通过查询到的数据转为echars的图表数据
目录
UV介绍
UV 是 Astral 公司开发的超高性能 Python 包管理工具,采用 Rust 实现,致力于替换传统工具(如 pip、pip-tools、Poetry 等),实现依赖管理、虚拟环境和构建的统一。
安装方式
- 官方脚本(推荐):
linux: curl -LsSf https://astral.sh/uv/install.sh | sh
| --- | --- |
windows: powershell -ExecutionPolicy ByPass -c "irm https://astral.sh/uv/install.ps1 | iex"
- 通过 pipx 安装:
pipx install uv
添加源
配置清华镜像(可选,提升国内网络速度):
[[index]]
url = "https://mirrors.tuna.tsinghua.edu.cn/pypi/web/simple/"
default = true
常用命令
## 1. 项目初始化
uv init <project-name>
uv init --package test_2 --python 3.10.9
## 2. 虚拟环境
uv venv --python 3.10.9
## 3. 激活虚拟环境
## macOS & Linux
source .venv/bin/activate
## Windows
.venv\Scripts\activate
## 4. 添加/删除依赖
uv add langgraph
uv remove langgraph
## 5. 同步环境
uv sync
## 6. 查看当前项目依赖树
uv tree
参考: 掘金 UV 介绍
| 操作 | 命令 | 说明 |
|---|---|---|
| 项目初始化 | uv init <project-name> |
初始化新项目 |
uv init --package test_2 --python 3.10.9 |
指定包名和 Python 版本初始化 | |
| 虚拟环境 | uv venv --python 3.10.9 |
创建指定 Python 版本的虚拟环境 |
| 激活虚拟环境 | source .venv/bin/activate(macOS/Linux) |
激活虚拟环境(macOS/Linux) |
.venv\Scripts\activate(Windows) |
激活虚拟环境(Windows) | |
| 添加/删除依赖 | uv add langgraph |
添加依赖(如 langgraph) |
uv remove langgraph |
删除依赖 | |
| 同步环境 | uv sync |
同步依赖到虚拟环境 |
| 查看依赖树 | uv tree |
显示当前项目的依赖树 |
LangGraph
LangGraph 是一个通过有向图(Directed StateGraph)编排 LLM 应用流程的 Python 框架,可用于高效构建多分支、状态复杂的智能应用。
官方文档: LangGraph 官方文档
环境准备
- 在
pyproject.toml的 dependencies 加入以下内容并执行uv sync:
dependencies = [
"fastapi>=0.115.12",
"langchain-community>=0.3.24",
"langchain[openai]>=0.3.25",
"langgraph>=0.4.5",
"loguru>=0.7.3",
"mysql-connector-python==9.0",
"pandas>=2.2.3",
"pymysql>=1.1.1",
"redis>=6.1.0",
"sse-starlette>=2.3.5",
"uvicorn>=0.34.2",
]
核心概念
LangGraph 采用 有向图 方式建模应用流程,主要包括以下核心要素:
- 节点(Node):流程中的原子操作单元,如 LLM 调用、工具函数、状态处理等。
- 普通节点:通常为一个 Python 函数。
- START 节点:特殊节点,表示用户输入入口。
- END 节点:特殊节点,表示流程终止。
- 边(Edge):定义节点间的数据流向与执行顺序,支持固定/条件分支等多种形式。
- 普通边:
add_edge- 条件边:
add_conditional_edges(选择性路由至多个节点或终止)- 条件入口点:通过
add_conditional_edges配合START节点实现
- 状态(State):在图中流动的数据载体,贯穿用户输入、中间结果、最终输出。
节点
- 方法:
add_node(node_name, node_function) - 参数:
node_name:节点唯一标识(字符串)。node_function:处理函数,接收当前状态(字典),返回更新后状态。
- 示例:
def process_input(state):
user_input = input("Enter something: ")
return {"user_input": user_input, "next_step": "analyze"}
graph.add_node("process_input", process_input)
连接节点(边)
- 方法:
add_edge(from_node, to_node) - 用途:定义节点间的固定执行顺序。
- 示例:
graph.add_edge("process_input", "analyze") # process_input 完成后执行 analyze
条件分支(动态边)
- 方法:
add_conditional_edges(from_node, condition_function, [to_nodes]) - 用途:根据条件动态选择下一个节点。
- 示例:
def route_based_on_age(state):
age = state.get("age", 0)
return "adult_path" if age >= 18 else "minor_path"
graph.add_conditional_edges("ask_age", route_based_on_age, ["adult_path", "minor_path"])
设置入口/终止点
set_entry_point(node_name):指定图的起始节点。set_finish_point(node_name):指定图的终止节点。- 说明:终止节点会结束流程,返回最终状态。
状态图编译
graph = graph_builder.compile(...)
状态(State)定义与更新
状态定义
可通过 TypedDict 或 Pydantic 定义数据结构:
## TypedDict 示例
from typing_extensions import TypedDict, Annotated
class State(TypedDict):
user_id: Annotated[str, lambda a, b: b]
name: Annotated[str, lambda a, b: b]
age: Annotated[int, lambda a, b: b]
other_info: Annotated[dict, lambda a, b: b]
## Pydantic 示例
from pydantic import BaseModel, Field
class PydanticState(BaseModel):
subjects: Annotated[list, operator.add] = Field(default=[], description="主题列表")
user_name: str = Field(..., description="用户姓名")
节点中手动更新状态
from langchain_core.messages import AIMessage, HumanMessage
from typing_extensions import TypedDict
class State(TypedDict):
messages: list[AnyMessage]
extra_field: int
def node(state: State):
new_message = AIMessage("Hello!")
return {"messages": state["messages"] + [new_message], "extra_field": 10}
graph = StateGraph(State).add_node(node).add_edge(START, "node").compile()
result = graph.invoke({"messages": [HumanMessage("Hi")]})
for message in result["messages"]:
message.pretty_print()
使用 Reducer 进行状态更新
from typing_extensions import Annotated
def add(left, right): return left + right
class State(TypedDict):
messages: Annotated[list[AnyMessage], add]
extra_field: int
def node(state: State):
new_message = AIMessage("Hello!")
return {"messages": [new_message], "extra_field": 10}
graph = StateGraph(State).add_node(node).add_edge(START, "node").compile()
result = graph.invoke({"messages": [HumanMessage("Hi")]})
for message in result["messages"]:
message.pretty_print()
send
在应用中,某些场景下上游节点会生成列表数据,下游节点逐项消费。send 用于将状态单独传递给目标节点。
- 参数:节点名、状态
- 示例代码见
send_graph.py -
Command
在同一节点中同时执行状态更新并决定下个节点。返回 Command,需标明类型注解:
from typing import Literal
def my_node(state: State) -> Command[Literal["node_a"]]:
return Command(
update={"foo": "bar"},
goto="node_a",
graph=Command.PARENT
)
graph=Command.PARENT:导航至最近父图
图的递归限制
为防止无限递归,LangGraph 支持设置单次运行的最大步骤数(默认25)。可通过 RunnableConfig 配置:
RunnableConfig(configurable={"thread_id": "1"}, recursion_limit=3)
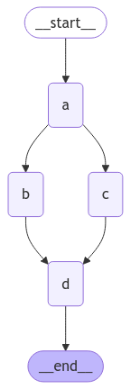
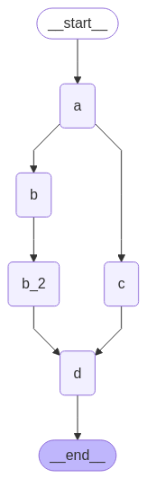
延迟执行
- 若同一轮有多个分支节点(如 b、c),可通过
defer=True控制下游节点延迟执行,确保所有分支完成后再执行。 - 不同设置对 d 节点执行次数有影响,详见示意图:
| 图一 | 图二 |
|---|---|
 |
|
 |
|
| b、c 并行后,d 在所有任务完成后执行 | b 有延伸节点,d 会执行两次;通过 defer 控制 |
图-线程持久化
LangGraph 内置持久层,自动实现检查点保存。每个检查点分配唯一 thread_id,可随时恢复状态。
- 线程配置示例:
{"configurable": {"thread_id": "1"}}
检查点
- 检查点是每个超级步骤的状态快照(StateSnapshot),包含 config、metadata、values、next、tasks 等信息。
- 详见文档
获取状态
## 获取最新状态
config = {"configurable": {"thread_id": "1"}}
graph.get_state(config)
## 获取指定 checkpoint_id
config = {"configurable": {"thread_id": "1", "checkpoint_id": "1ef663ba-28fe-6528-8002-5a559208592c"}}
graph.get_state(config)
## 获取历史记录
config = {"configurable": {"thread_id": "1"}}
list(graph.get_state_history(config))
添加持久化
参考官方文档:添加短时记忆
示例-利用检测点实现人机交互
- 示例代码:
demo_2.py -
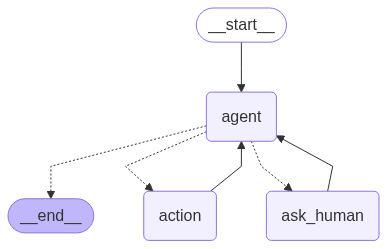
图节点的流式输出
| 模式 | 描述 |
| — | — |
| values | 每步后流式传输完整状态值 |
| updates | 每步后流式传输状态更新内容 |
| custom | 节点内部流式传输自定义数据 |
| messages | LLM 节点流式传输 (token, metadata) 二元组 |
| debug | 全流程调试信息流式传输 |
- 使用方式:
for chunk in graph.stream(inputs, stream_mode="updates"):
print(chunk)
## 异步:
async for chunk in graph.astream(inputs, stream_mode="updates"):
print(chunk)
- 支持多模式组合:
for mode, chunk in graph.stream(inputs, stream_mode=["updates", "custom"]):
print(chunk)
async for mode, chunk in graph.astream(inputs, stream_mode=["updates", "custom"]):
print(chunk)
- 包含子图输出:
for chunk in graph.stream(
{"foo": "foo"},
subgraphs=True,
stream_mode="updates",
):
print(chunk)
- 按节点过滤:
for msg, metadata in graph.stream(
inputs,
stream_mode="messages",
):
if msg.content and metadata["langgraph_node"] == "some_node_name":
print(msg.content)
流式传输自定义数据
- 用
get_stream_writer()获取流写入器,发出自定义数据。 stream_mode="custom"时.stream()或.astream()可获取自定义数据。
Python 3.11 以下不支持
get_stream_writer()异步用法。可通过 writer 手动传递。
from typing import TypedDict
from langgraph.config import get_stream_writer
from langgraph.graph import StateGraph, START
class State(TypedDict):
query: str
answer: str
def node(state: State):
writer = get_stream_writer()
writer({"custom_key": "Generating custom data inside node"})
return {"answer": "some data"}
graph = (
StateGraph(State)
.add_node(node)
.add_edge(START, "node")
.compile()
)
inputs = {"query": "example"}
for chunk in graph.stream(inputs, stream_mode="custom"):
print(chunk)
示例代码
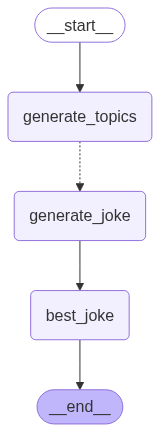
图构建示例
- 示例代码:
demo_1.py
| 图片 | 方法 |
|---|---|
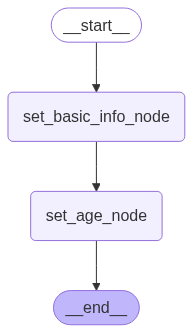 |
get_app_1 |
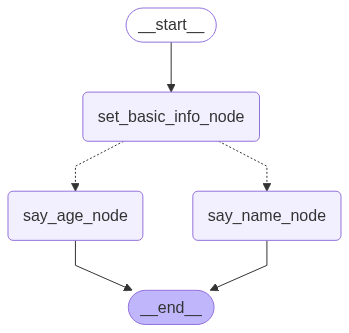 |
get_app_2 |
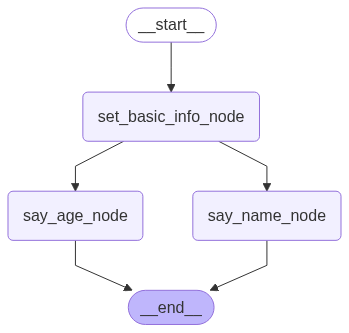 |
get_app_3 |
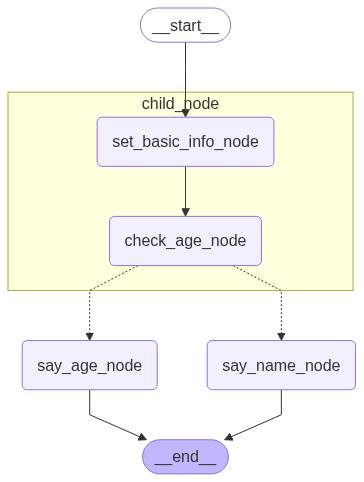 |
get_app_4 |
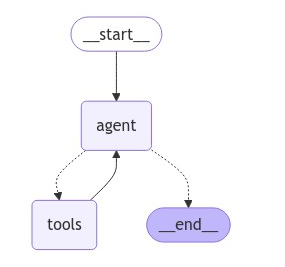 |
react_agent_demo.py |